Traitement et Analyse Informatiques de Données Biologiques (STAT0077)
TP 5: Statistique avec R
Prof. Patrick E. Meyer
Version 2.0
- Créer un jeu de données de 20 échantillons avec deux variables aléatoires binomiales indépendantes qui peuvent prendre deux valeurs, de manière équilibrée.
- Recommencer cette opération avec 5000 échantillons (sauver ces données dans une variable différente de la précédente).
- Comparer ces deux jeux de données avec la fonction
table().
- Quel jeux de données est empiriquement plus proche du résultat théorique attendu?
- Créer un jeu de données de 200 échantillons avec deux variables aléatoires normales
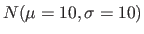 et
et
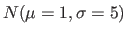 .
.
- En utilisant la fonction
quantile, identifier les échantillons qui sont dans le quartile supérieur de la première variable et dans le tercile inférieur de la seconde variable.
- Refaites l'exercice précédent avec la fonction
norm adéquate. Quelle est la différence entre cette stratégie-ci (norm) et la précédente (quantile)?
Soit un modèle prédictif qui prédit sur 100 patients ceux qui sont malades. Il s'avère que sur les 100 patients, 50 sont en réalité malades. Le modèle prédit 30 malades et 25 de ces prédictions sont correctes.
- Quelle est la probabilité d'obtenir le même résultat par chance?
- Quelle est la probabilité d'obtenir un résultat au moins aussi extrême que celui-là, par chance?
- Soit X une variable aléatoire normale
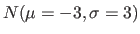 , Y une variable aléatoire normale
, Y une variable aléatoire normale
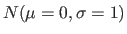 , V = exp(X), Z = sin(X) et W = X+Y, chacune ayant 1000 échantillons:
, V = exp(X), Z = sin(X) et W = X+Y, chacune ayant 1000 échantillons:
- Comparer la corrélation de Pearson, Kendall et Spearman entre toutes ces variables.
- Expliquer à l'aide d'un scatterplot pour chacune des paires de variables, les résultats de corrélation obtenus.
- Un jeu de données d'expressions génétiques est stocké dans le fichier
testset3.Rdata situé dans le répertoire du cours qui est dans le répertoire /public/ du serveur.
Dans ce jeu de données, les colonnes représentent des gènes de E.coli dont l'activité est mesurées lors de différents stress (chaque ligne représente un stress différent).
Autrement dit, chaque valeur [i,j] du dataset est un nombre entre 0 et 1 qui représente la production d'ARN (appelée aussi l'activité) du gène i dans l'expérience/stress j.
Identifier le gène de votre jeu de données qui a la plus grande dépendance avec le premier gène (CAD la première colonne), en utilisant la corrélation de Pearson.
<--- BACK