Analyse de données avec R
TP 5: Gestion des fichiers et graphiques (2h)
Prof. Patrick E. Meyer
Version 3.0
- Soit X une variable aléatoire normale
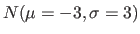 , Y une variable aléatoire normale
, Y une variable aléatoire normale
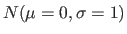 , V = exp(X), Z = sin(X) et W = X+Y, chacune ayant 1000 échantillons (créez ce data.frame):
, V = exp(X), Z = sin(X) et W = X+Y, chacune ayant 1000 échantillons (créez ce data.frame):
- Comparer la corrélation de Pearson, Kendall et Spearman entre toutes ces variables.
- Expliquer à l'aide d'un scatterplot pour chacune des paires de variables, les résultats de corrélation obtenus.
A l'aide des fonctions data(),pairs(), plot(), lines(),
title(), pdf() et dev.off()
Charger le dataset CO2 et
- Écrire un code R qui écrit le contenu du dataset CO2, avec des points virgules comme séparateur et des virgules pour les décimales, dans un fichier nommé mondataset.txt.
- Charger le dataset mondataset.txt dans une variable mydata avec les noms de lignes et colonnes adéquatement formatés (identique à CO2).
- Visualisez graphiquement les relations entre toutes les paires de variables parmi
$Type, $Treatment,$conc et $uptake (la fonction pairs() sera utile).
- Dans le graphique obtenu, choisissez la paire de variables qui vous semble la plus pertinente et re-dessinez ce graphique avec la fonction
plot.
- Ajoutez, en pointillé vert, une diagonale du graphique, ainsi qu'un titre (en noir) ayant du sens (les fonctions lines() et title() seront utiles).
- Sauvez le graphique dans un fichier .pdf et vérifiez le résultat obtenu dans le fichier spécifié.
- Écrire un code R qui crée un vecteur contenant le maximum d'absorption atteint par chaque type de plante du dataset interne
CO2 (boucle implicite).
- Faites un
barplot avec les minima et maxima d'absorption pour chaque type de plantes du dataset CO2, mettez y des couleurs et titres appropriés.
<--- BACK