Traitement et Analyse Informatiques de Données Biologiques (STAT0077)
TP 6: p-values avec R
Prof. Patrick E. Meyer
Version 2.0
Pour chaque exercice générant des valeurs aléatoires, "synchroniser votre code" avec la commande set.seed(100).
- Avec la fonction
t.test() comparer les moyennes entre trois échantillonages de 50 mesures. Le premier doit provenir d'une distribution gaussienne centrée en 0, le second d'une centrée en 0.1 et le troisième d'une centrée en 1. L'écrat-type de ces trois distributions normales est identique: 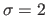 .
.
- Combien d'échantillons vous faut-il, à peu près, empiriquement, pour rejeter l'hypothèse nulle une fois sur deux, lorsque vous comparez une distribution gaussienne centrée en 0 et une centrée en 1.
- A l'aide de la fonction
power.t.test() identifier combien d'échantillons sont nécessaires théoriquement pour atteindre cette puissance de 50% pour ces mêmes valeurs.
- Ecrire un extrait de code qui compare 100 expériences, chacune de 40 mesures générées avec une distribution uniforme
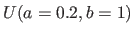 , avec une expérience de référence, également de 40 mesures mais générées à partir d'une distribution uniforme
, avec une expérience de référence, également de 40 mesures mais générées à partir d'une distribution uniforme 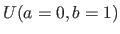 . Garder en mémoire le vecteur des 100 p-values et compter le nombre de succès (qui identifie correctement le statut de l'hypothèse nulle avec un seuil à 0.05).
. Garder en mémoire le vecteur des 100 p-values et compter le nombre de succès (qui identifie correctement le statut de l'hypothèse nulle avec un seuil à 0.05).
- Charger le dataset
PlantGrowth et comparer adéquatement les moyennes des biomasses dans chacun des groupes.
- Charger le dataset
CO2 et comparer adéquatement les moyennes des absorptions en CO2 entre les plantes ayant reçu un traitement refroidissant la veille, et les autres.
<--- BACK